
One of the more exciting connectivity standards over the past year has been CXL. Built upon a PCIe physical foundation, CXL is a connectivity standard designed to handle much more than what PCIe does – aside from simply acting as a data transfer from host to device, CXL has three branches to support, known as IO, Cache, and Memory. As defined in the CXL 1.0 and 1.1 standards, these three form the basis of a new way to connect a host with a device. The new CXL 2.0 standard takes it a step further.
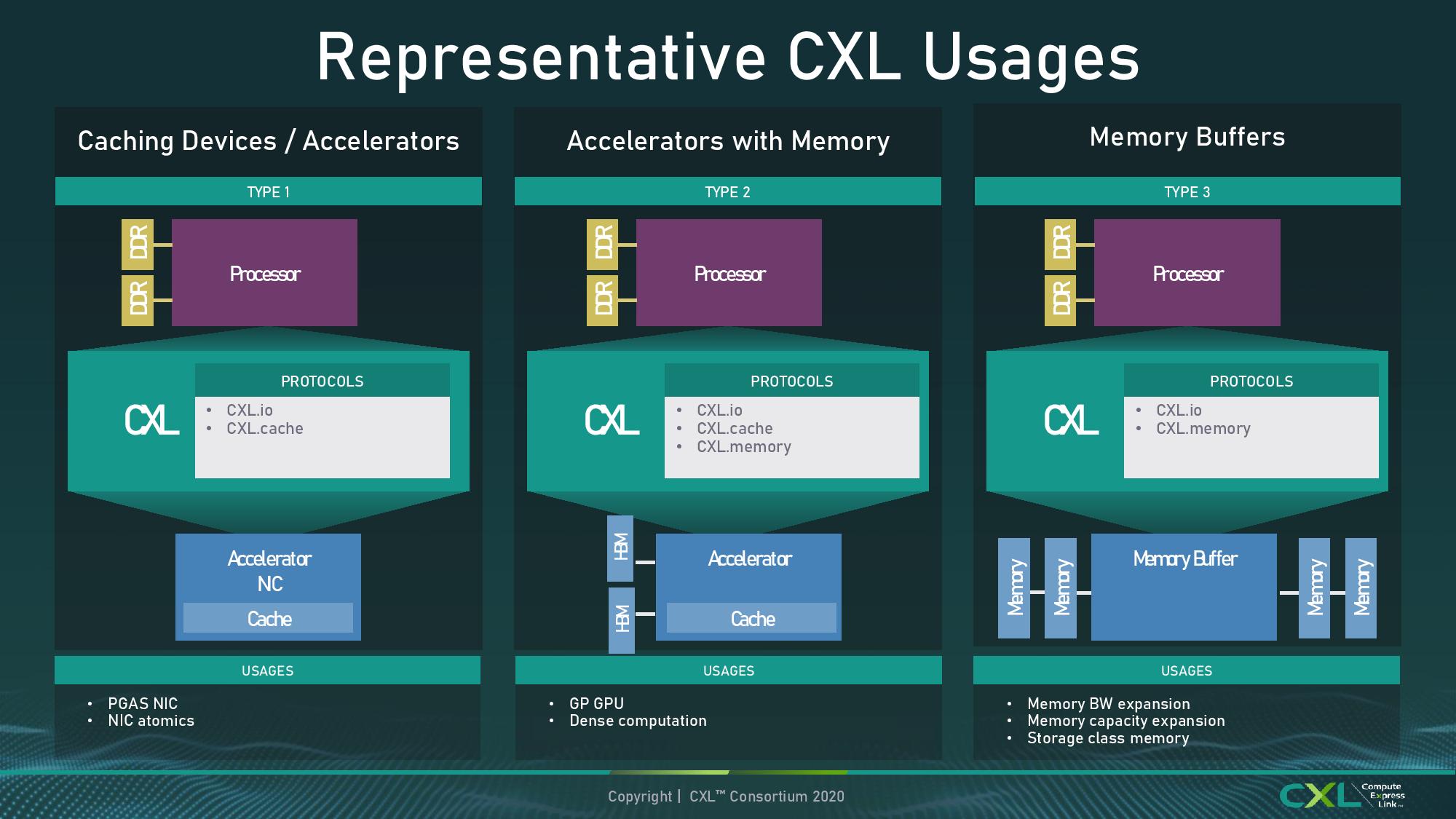
CXL 2.0 is still built upon the same PCIe 5.0 physical standard, which means that there aren’t any updates in bandwidth or latency, but adds some much needed functionality that customers are used to with PCIe. At the core of CXL 2.0 are the same CXL.io, CXL.cache and CXL.memory intrinsics, dealing with how data is processed and in what context, but with added switching capabilities, added encryption, and support for persistent memory.
CXL 2.0 Switching
For users who are unfamiliar with PCIe switches, these connect to a host processor with a number of lanes, such as eight lanes or sixteen lanes, and then support many more lanes downstream to increase the number of supported devices. A standard PCIe switch for example might connect with 16x lanes to the CPU, but offer 48 PCIe lanes downstream to enable six GPUs connected at x8 apiece. There is an upstream bottleneck, but for workloads that rely on GPU-to-GPU transfer, especially on systems with limited CPU lanes, using a switch is the best way to go. CXL 2.0 now enables the standard for switching.
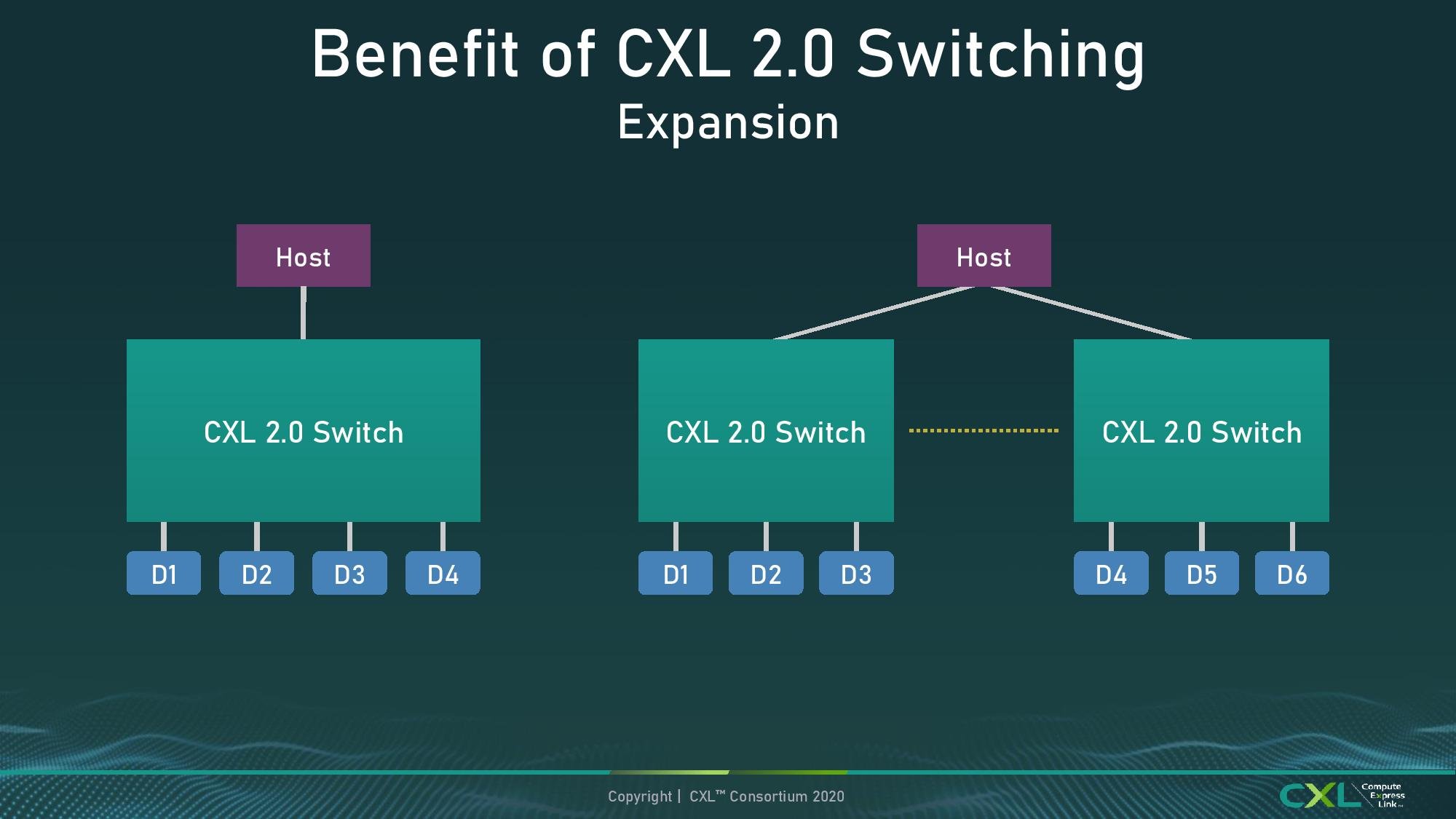
Modern PCIe switches do more than just ‘add lanes’. Should one of the end-point devices fail (such as an NVMe SSD), then the switch ensures the system can still run and disable that lane so it doesn’t affect the rest of the system. Current switches in the market also support switch-to-switch connectivity, allowing a system to scale out downstream devices.
One of the bigger updates in recent switch products has been the support for multiple upstream hosts, such that if a host fails, the downstream devices still have another host to connect to. Combined with switch-to-switch connectivity, a system can have a series of pooled hosts and pooled devices. Each device can work specifically with a host in the pool in a 1:1 relationship, or the devices can work with many hosts. The new standard, with CXL Switching Fabric APIs, enable up to 16 hosts to use one downstream CXL device at once. On top of this, Quality of Service (QoS) is a part of the standard, and in order to enable this the standard packet/FLIT unit of data transfer is unaltered, with some of the unused bits from CXL 1.1 being used (this is what extra bits are used for!).

The one element not present in CXL 2.0 is multi-layer switch topologies. At present the standard and API only supports a flat layer. In our briefing, the consortium members (some of whom already create multi-layer PCIe switch fabrics) stated that this is the first stage of enabling switch mechanics, and the roadmap will develop based on customer needs.
CXL 2.0 Persistent Memory
Another notch in enterprise computing in the last few years is persistent memory – something almost as fast as DRAM but stores data like NAND. There has always been a question of where such memory would sit: either as small fast storage through a storage-like interface, or as slow high-capacity memory through a DRAM interface. The initial CXL standards did not directly support persistent memory, unless it already had a device attached to it, in the CXL.memory standard. This time however, CXL 2.0 enables distinct PMEM support as part of a series of pooled resources.
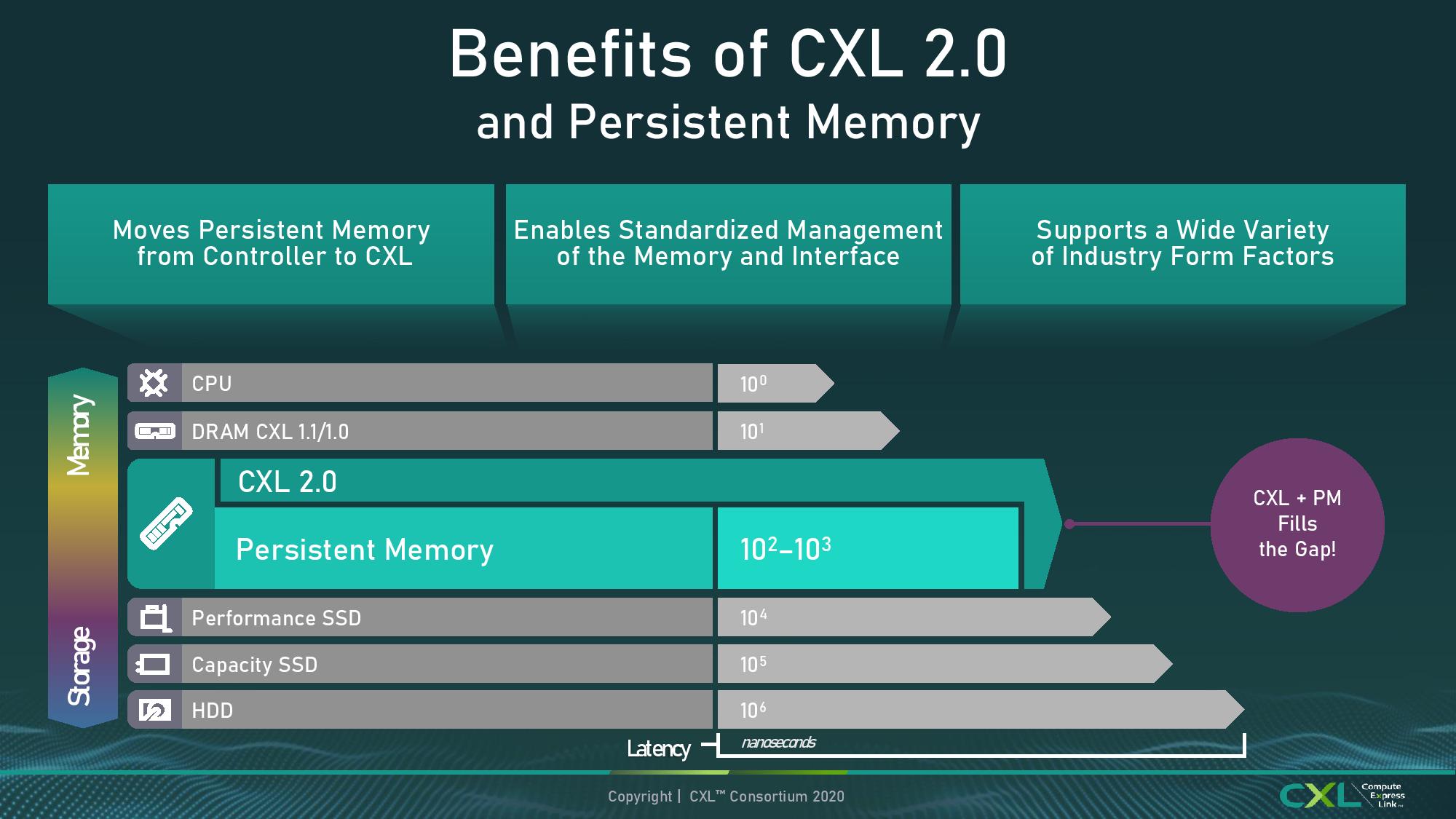
The APIs enabling software to deal with PMEM support are built into the specification, allowing persistent memory pools to be accessed either in ‘App Direct’ mode as a separate storage tier, or as a ‘Memory Direct’ mode which expands the host DRAM pool. The goal here is more to do with tiered storage management with whichever way that CXL consortium member customers need for their application, so the goal is for the standard to support as much as possible, and then over time improve those that gain traction.
The Persistent Memory aspect draws parallels with Intel’s DC Persistent Memory Optane products, and the goal here is to use them in more-or-less the same way, except this time there is direct support through CXL interfaces and CXL switches, making the pools of memory or storage available system wide, rather than just to a singular host (or through a PCIe interface to a pool).
CXL 2.0 Security (optional)
The last, but arguably most important feature update for some, is point-to-point security for any CXL link. The CXL 2.0 standard now supports any-to-any communication encryption through the use of hardware acceleration built into the CXL controllers. This is an optional element to the standard, meaning that silicon providers do not have to build it in, or if it is built in, then it can be enabled/disabled, however in the briefing I was told that it is expected that most if not all of the ecosystem that builds on CXL 2.0 will use it – or at least have it as an option to enable.
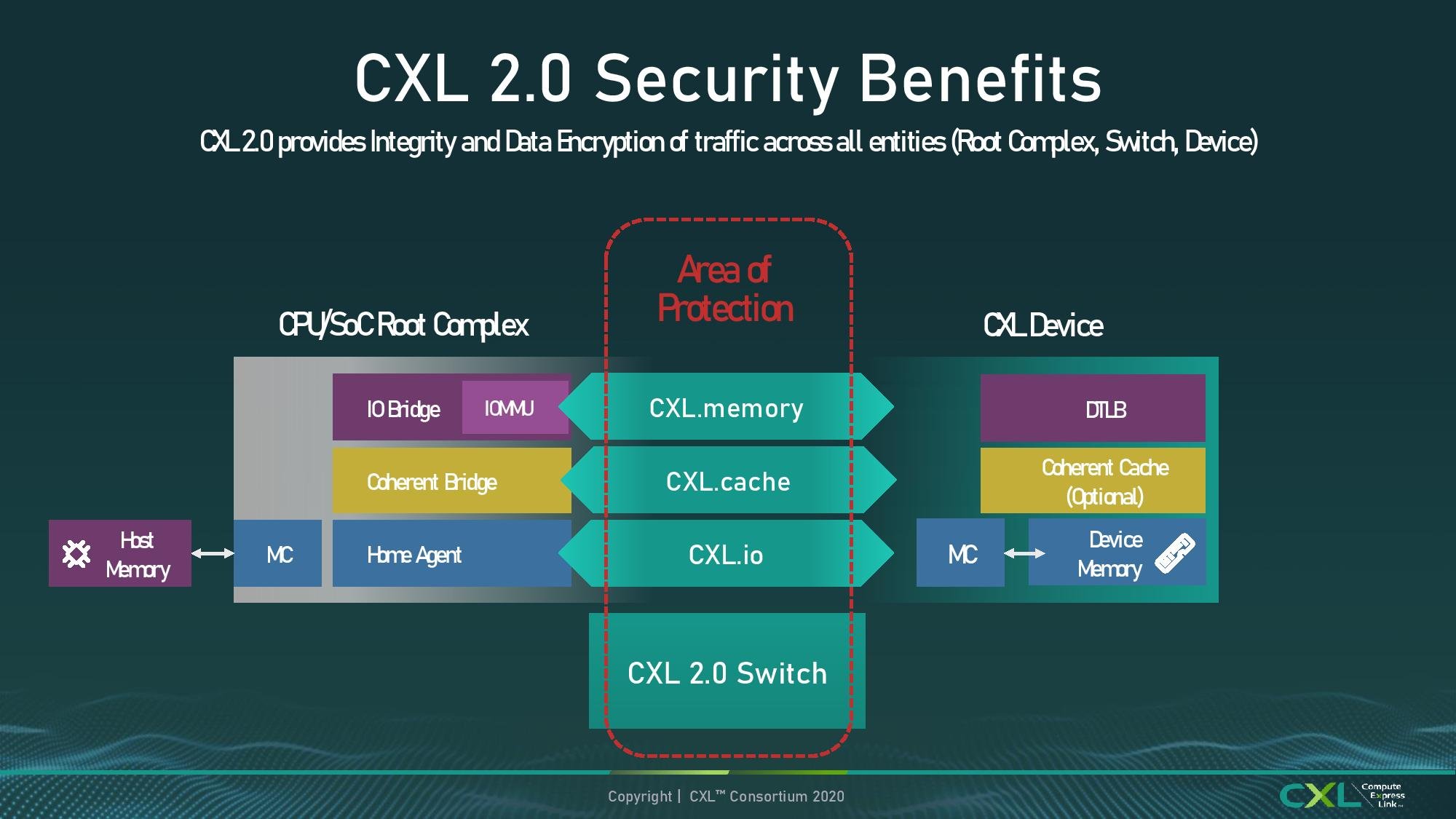
When asked about hits to latency, I was informed there is a hit to latency, however it will depend on the exact use case if it is enabled. No hard numbers were given, but I was told that customers that need the highest latency, who can ensure safety in the system, will likely have it disabled, whereas those who need it to conform to customer requests, or for server-to-server communications, are likely to use it.
CXL 2.0 and CXL Roadmap
The initial part of the discussion about CXL 2.0 with two of the consortium members started with explaining that the CXL roadmap is designed to both meet the demands and trends of the market, while still adhering to customer requests from consortium members. This means trends in server disaggregation, or more storage bandwidth, has led to features such as switching and persistent memory support. CXL is committed to enabling open industry standards, even as they scope out next-gen CXL.
I asked about this physical layer tie in with PCIe, and where the consortium sees that evolving. I was told that currently there are no plans to deviate away from the PCIe physical specification – there would have to be a strong pull and a strong need to go and build another physical layer topology, which would also break backwards compatibility (which is apparently a cornerstone of CXL). It should be noted that all CXL devices are expected to have PCIe fallback, however some/most/all of the key features in PCIe mode might be lost, depending on the product.
We have still yet to see any CXL products come to market, even 1.0/1.1, mostly due to the requirement of having a PCIe 5.0 physical interface. Intel has already stated that Sapphire Rapids will support CXL 1.1, however that is still a while away. Speaking with our consortium contacts, they stated that for any consortium member looking to build a CXL host or device or switch today, then it is expected that they will follow the CXL 2.0 specification. For a lot of consortium members, there is still learning to do with CXL silicon – proofs of concepts are still in the works. It should be noted that any CXL 2.0 product is backwards compatible with CXL 1.0/1.1 – the standard is designed this way.
Next week is the annual Supercomputing conference, focusing on high-performance computing. This would be a key arena for some of the CXL consortium members to make announcements, should any of them start to talk about CXL products or CXL 2.0 roadmaps.