
If you like to sing and are constantly looking for your own accompaniment track that you can sing along, you may like this new open-source tool a lot.
Released not long ago, Spleeter is an open-source tool that can be used to separate a soundtrack in vocals and accompaniment. It uses the Deezer source separation library with pre-trained models written in Python and uses Tensorflow.

Spleeter is designed to be used straight from the command-line. Yes, it works more seamlessly in a Linux environment but you can do so on Windows too.
Here is how to get started.
First of all, we need to install Anaconda, the data science platform with all the libraries, packages, and tools needed for this project. One of the tools included in Anaconda is the Conda, the open-source package management system. And that’s the tool that we will use to install Spleeter.
Open Anaconda Prompt, from Start > Anaconda > Anaconda Prompt.

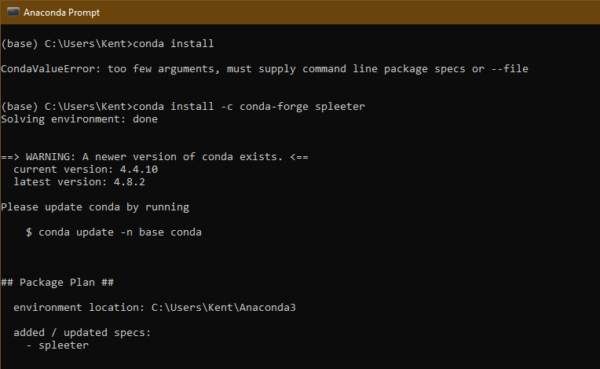
And run the following to install Spleeter.
conda install -c conda-forge spleeter
Now, it’s time to finally make your own karaoke soundtrack.
spleeter separate -i sourcesound.mp3 -o audio_output
By default, it uses the 2stems model that will just separate the original sound with the vocals and the accompaniment. The output contains two files: accompaniment.wav and vocals.wav.
There is also a pre-trained 4-stem (vocals / bass / drums / other) too:
spleeter separate -i sourcesound.mp3 -o audio_output -p spleeter:4stems
It generates 4 files this time: vocals.wav, drums.wav, bass.wav, and other.wav.
If you also would like a separate piano track, there is a 5-stem model.
spleeter separate -i sourcesound.mp3 -o audio_output -p spleeter:5stems
Check out more details here for other models.
It all seems quite complicated at first but when I really started to piece it all together, it’s actually fairly straightforward. What’s more important, the result is amazing.