
30-second summary:
- As Google increasingly favors sites with content that exudes expertise, authority, and trustworthiness (E-A-T), it is imperative that SEOs and marketers produce content that is not just well written, but that also demonstrates expertise.
- How do you understand what topics and concerns matter most to your customer base?
- Can you use Q&As to inform content strategies?
- XPath notations can be your treasure trove.
- Catalyst’s Organic Search Manager, Brad McCourt shares a detailed guide on using XPath notations and your favorite crawler to quickly obtain the Q&As in a straightforward and digestible format.
As Google increasingly favors sites with content that exudes expertise, authority, and trustworthiness (E-A-T), it is imperative that SEOs and marketers produce content that is not just well written, but that also demonstrates expertise. One way to demonstrate expertise on a subject or product is to answer common customer questions directly in your content.
But, how do you identify what those questions are? How do you understand what topics and concerns matter most?
The good news is that they are hiding in plain sight. Chances are, your consumers have been shouting at the top of their keyboards in the Q&A sections of sites like Amazon.

These sections are a treasure trove of (mostly) serious questions that real customers have about the products you are selling.
How do you use these Q&As to inform content strategies? XPath notation is your answer.
You can use XPath notations and your favorite crawler to quickly obtain the Q&As in a straightforward and digestible format. XPath spares you from clicking through endless screens of questions by automating the collection of important insights for your content strategy.
What is XPath?
XML Path (XPath) is a query language developed by W3 to navigate XML documents and select specified nodes of data.
The notation XPath uses is called “expressions”. Using these expressions, you can effectively pull any data that you need from a website as long as there is a consistent structure between webpages.
This means you can use this language to pull any publicly available data in the source code, including questions from a selection of Amazon Q&A pages.
This article is not meant to be a comprehensive tutorial on XPath. For that, there are plenty of resources from W3. However, XPath is easy enough to learn with only knowing the structure of XML and HTML documents. This is what makes it such a powerful tool for SEOs regardless of coding prowess.
Let’s walk through an example to show you how…
Using XPath to pull customer questions from Amazon
Pre-req: Pick your web crawler
While most of the big names in web crawling – Botify, DeepCrawl, OnCrawl – all offer the ability to extract data from the source code, I will be using ScreamingFrog in the example below.
ScreamingFrog is by far the most cost-effective option, allowing you to crawl up to 500 URLs without buying a license. For larger projects you can buy a license. This will allow you to crawl as many URLs as your RAM can handle.
Step one: Collect the URLs to crawl
For our example, let’s pretend we’re doing research on the topics we should include in our product pages and listings for microspikes. For those unaware, microspikes are an accessory for your boots or shoes. They give you extra grip in wintry conditions, so they are particularly popular among cold-weather hikers and runners.

Source: https://www.amazon.com/s?k=microspikes
Here we have a list of 13 questions and answer pages for the top microspike pages on Amazon.com. Unfortunately, there is some manual work required to create the list.

The easiest way is to search for the topic (that is, microspikes) and pull links to the top products listed. If you have the product’s ASIN (Amazon Standard Identification Number) handy, you can also generate the URLs using the above format, but switching out the ASIN.
Step two: Determine the XPath
From here, we need to determine the XPath.
In order to figure out the proper XPath notation to use to pull in the desired text, we have two main options:
- View the Source-Code

- View the rendered source code and copy the XPath directly from Chrome’s Inspect Element tool

You’ll find that the expression needed to locate all questions in an Amazon Q&A page is:
//span[@class=”a-declarative”]
Here is XPath notation broken down:
- // is used to locate all instances of the following expression.
- Span is the specific tag we’re trying to locate. //span will locate every single <span> tag in the source code. There are over 300 of these, so we’ll need to be more specific.
- @class specifies that //span[@class] will ensure all <span> tags with an assigned class attribute will be located.
- @class=”a-declarative” dictates that //span[@class=”a-declarative”] only locates <span> tags where the class attribute is set to “a-declarative” – that is, <span class=”a-declarative”>
There is an extra step in order to return the inner text of the specified tag that is located, but ScreamingFrog does the heavy lifting for us.
It’s important to note that this will only work for Amazon Question and Answer pages. If you wanted to pull questions from, say, Quora, TripAdvisor, or any other site, the expression would have to be adjusted to locate the specific entity you desire to collect on a crawl.
Step three: Configure your crawler
Once you have this all set, you can then go into ScreamingFrog.
Configuration -> Custom -> Extraction

This will then take you to the Custom Extraction screen.

This is where you can:
- Give the extraction a name to make it easier to find after the crawl, especially if you’re extracting more than one entity. ScreamingFrog allows you to extract multiple entities during a single crawl.
- You can then choose the extraction method. In this article, it is all about XPath, but you also have the option of extracting data via CSSPath and REGEX notation as well.
- Place the desired XPath expression in the “Enter XPath” field. ScreamingFrog will even check your syntax for you, providing a green checkmark if everything checks out.
- You then have the option to select what you want extracted, be it the full HTML element or the HTML found within the located tag. For our example, we want to extract the text in between any <span> tags with a class attribute set to “a-declarative” so we select “extract text.”
We can then click OK.
Step four: Crawl the desired URLs
Now it’s time to crawl our list of Amazon Q&A pages for microspikes.
First, we’ll need to switch the Mode in ScreamingFrog from “Spider” to “List.”
Then, we can either add our set of URLs manually or upload them from an Excel or other supported format.
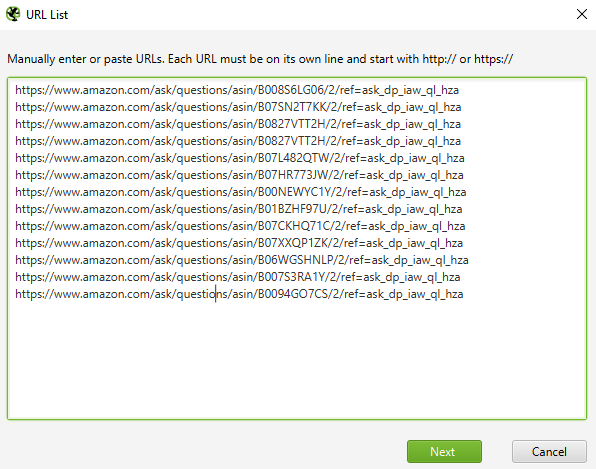
After we confirm the list, ScreamingFrog will crawl each URL we provided, extracting the text between all <span> tags containing the class attribute set to “a-declarative.”
In order to see the data collected, you just need to select “Custom Extraction” in ScreamingFrog.

At first glance, the output might not look that exciting.
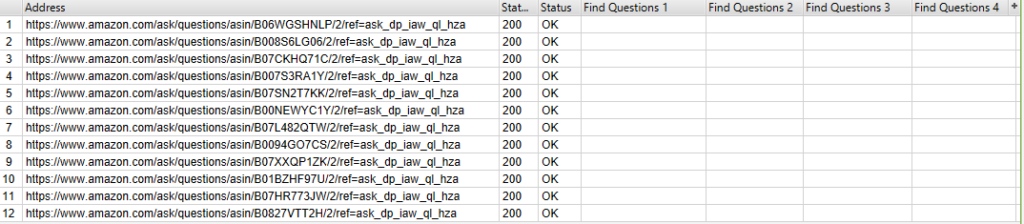
However, this is only because a lot of unneeded space is included with the data, so you might see some columns that appear blank if they are not expanded to fully display the contents.
Once you copy and paste the data into Excel or your spreadsheet program of choice, you can finally see the data that has been extracted. After some clean-up, you get the final result:

The result is 118 questions that real customers have asked about microspikes in an easily accessible format. With this data at your fingertips, you’re now ready to incorporate this research into your content strategy.
Content strategies
Before diving into content strategies, a quick word to the wise: you can’t just crawl, scrape and publish content from another site, even if it is publicly accessible.
First, that would be plagiarism and expect to be hit with an DMCA notice. Second, you’re not fooling Google. Google knows the original source of the content, and it is extremely unlikely your content is going to rank well – defeating the purpose of this entire strategy.
Instead, this data can be used to inform your strategy and help you produce high quality, unique content that users are searching for.
Now, how do you get started with your analysis?
I recommend first categorizing the questions. For our example there were many questions about:
- Sizing: What size microspikes are needed for specific shoe/boot sizes?
- Proper Use – Whether or not microspikes could be used in stores, on slippery roofs, while fishing, mowing lawns, or for walking on plaster?
- Features: Are they adjustable, type of material, do they come with a carrying case?
- Concerns: Are they comfortable, do they damage your footwear, do they damage the type of flooring/ground you’re on, durability?
This is an amazing insight into the potential concerns customers might have before purchasing microspikes.
From here, you can use this information to:
1. Enhance existing content on your product and category pages
Incorporate the topics into the product or category descriptions, answering questions shoppers might have pre-emptively.
For our example, we might want to make it abundantly clear how sizing works – including a sizing chart and specifically mentioning types of footwear the product may or may not be compatible with.
2. Build out a short on-page FAQ section featuring original content, answering commonly asked questions
Make sure to implement FAQPage Schema.org markup for a better chance to appear for listings like People Also Ask sections, which are increasingly taking up real estate in the search results.
For our example, we can answer commonly asked questions about comfort, damage to footwear, durability, and adjustability. We could also address if the product comes with a carrying case and how to best store the product for travel.
3. Produce a product guide, incorporating answers to popular questions surrounding a product or category
Another strategy is to produce an extensive one-stop product guide showcasing specific use cases, sizing, limitations, and features. For our example, we could create specific content for each use case like hiking, running in icy conditions, and more.
Even better, incorporate videos, images, charts, and featured products with a clear path to purchase.
Using this approach your end product will be content that shows expertise, the authority on a subject, and most importantly, addresses customer concerns and questions before they even think to ask. This will help prevent your customers from having to do additional research or contact customer service. Thanks to your informative and helpful content, they will be more ready to make a purchase.
Furthermore, this approach also has the potential to lower product return rates. Informed customers are less likely to purchase the wrong product based upon assumed or incomplete knowledge.
Conclusion
Amazon is just the tip of the iceberg here. You can realistically apply this strategy to any site that has publicly accessible data to extract, be that questions from Quora about a product category, Trip Advisor reviews about hotels, music venues, and attractions, or even discussions on Reddit.
The more informed you are about what your customers are expecting when visiting your site, the better you can serve those expectations, motivate purchases, decrease bounces, and improve organic search performance.
The post How to use XPath expressions to enhance your SEO and content strategy appeared first on Search Engine Watch.