
The web is in a golden age of front-end development, and JavaScript and technical SEO are experiencing a renaissance. As a technical SEO specialist and web dev enthusiast at an award-winning digital marketing agency, I’d like to share my perspective on modern JavaScript SEO based on industry best practices and my own agency experience. In this article, you’ll learn how to optimize your JS-powered website for search in 2021.
What is JavaScript SEO?
JavaScript SEO is the discipline of technical SEO that’s focused on optimizing websites built with JavaScript for visibility by search engines. It’s primarily concerned with:
- Optimizing content injected via JavaScript for crawling, rendering, and indexing by search engines.
- Preventing, diagnosing, and troubleshooting ranking issues for websites and SPAs (Single Page Applications) built on JavaScript frameworks, such as React, Angular, and Vue.
- Ensuring that web pages are discoverable by search engines through linking best practices.
- Improving page load times for pages parsing and executing JS code for a streamlined User Experience (UX).
Is JavaScript good or bad for SEO?
It depends! JavaScript is essential to the modern web and makes building websites scalable and easier to maintain. However, certain implementations of JavaScript can be detrimental to search engine visibility.

How does JavaScript affect SEO?
JavaScript can affect the following on-page elements and ranking factors that are important for SEO:
- Rendered content
- Links
- Lazy-loaded images
- Page load times
- Meta data
What are JavaScript-powered websites?
When we talk about sites that are built on JavaScript, we’re not referring to simply adding a layer of JS interactivity to HTML documents (for example, when adding JS animations to a static web page). In this case, JavaScript-powered websites refer to when the core or primary content is injected into the DOM via JavaScript.
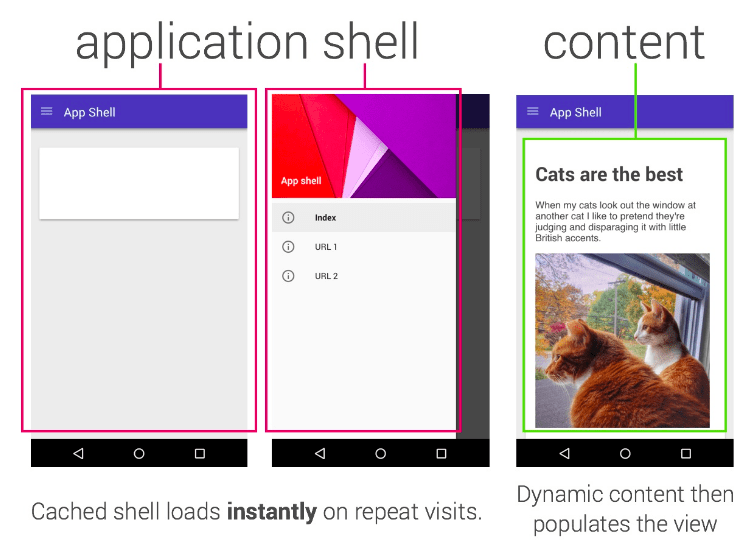
This template is called an app shell and is the foundation for progressive web applications (PWAs). We’ll explore this next.
How to check if a site is built with JavaScript
You can quickly check if a website is built on a JavaScript framework by using a technology look-up tool such as BuiltWith or Wappalyzer. You can also “Inspect Element” or “View Source” in the browser to check for JS code. Popular JavaScript frameworks that you might find include:
JavaScript SEO for core content
Here’s an example: Modern web apps are being built on JavaScript frameworks, like Angular, React, and Vue. JavaScript frameworks allow developers to quickly build and scale interactive web applications. Let’s take a look at the default project template for Angular.js, a popular framework produced by Google.
When viewed in the browser, this looks like a typical web page. We can see text, images, and links. However, let’s dive deeper and take a peek under the hood at the code:
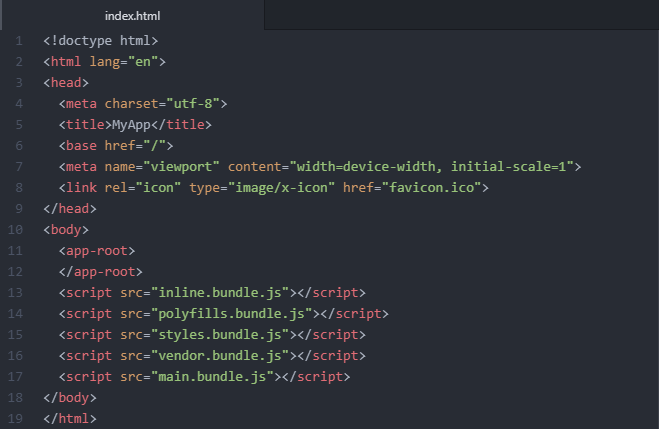
Now we can see that this HTML document is almost completely devoid of any content. There are only the app-root and a few script tags in the body of the page. This is because the main content of this single page application is dynamically injected into the DOM via JavaScript. In other words, this app depends on JS to load key on-page content!
Potential SEO issues: Any core content that is rendered to users but not to search engine bots could be seriously problematic! If search engines aren’t able to fully crawl all of your content, then your website could be overlooked in favor of competitors. We’ll discuss this in more detail later.
JavaScript SEO for internal links
Besides dynamically injecting content into the DOM, JavaScript can also affect the crawlability of links. Google discovers new pages by crawling links it finds on pages.
As a best practice, Google specifically recommends linking pages using HTML anchor tags with href attributes, as well as including descriptive anchor texts for the hyperlinks:

However, Google also recommends that developers not rely on other HTML elements — like div or span — or JS event handlers for links. These are called “pseudo” links, and they will typically not be crawled, according to official Google guidelines:

Despite these guidelines, an independent, third-party study has suggested that Googlebot may be able to crawl JavaScript links. Nonetheless, in my experience, I’ve found that it’s a best practice to keep links as static HTML elements.
Potential SEO issues: If search engines aren’t able to crawl and follow links to your key pages, then your pages could be missing out on valuable internal links pointing to them. Internal links help search engines crawl your website more efficiently and highlight the most important pages. The worst-case scenario is that if your internal links are implemented incorrectly, then Google may have a hard time discovering your new pages at all (outside of the XML sitemap).
JavaScript SEO for lazy-loading images
JavaScript can also affect the crawlability of images that are lazy-loaded. Here’s a basic example. This code snippet is for lazy-loading images in the DOM via JavaScript:
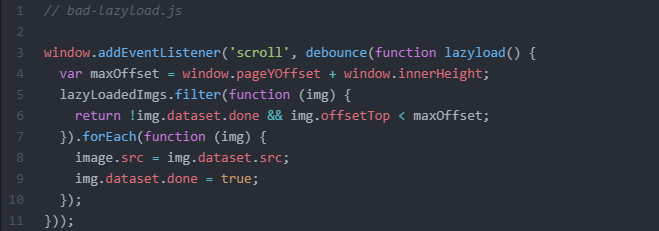
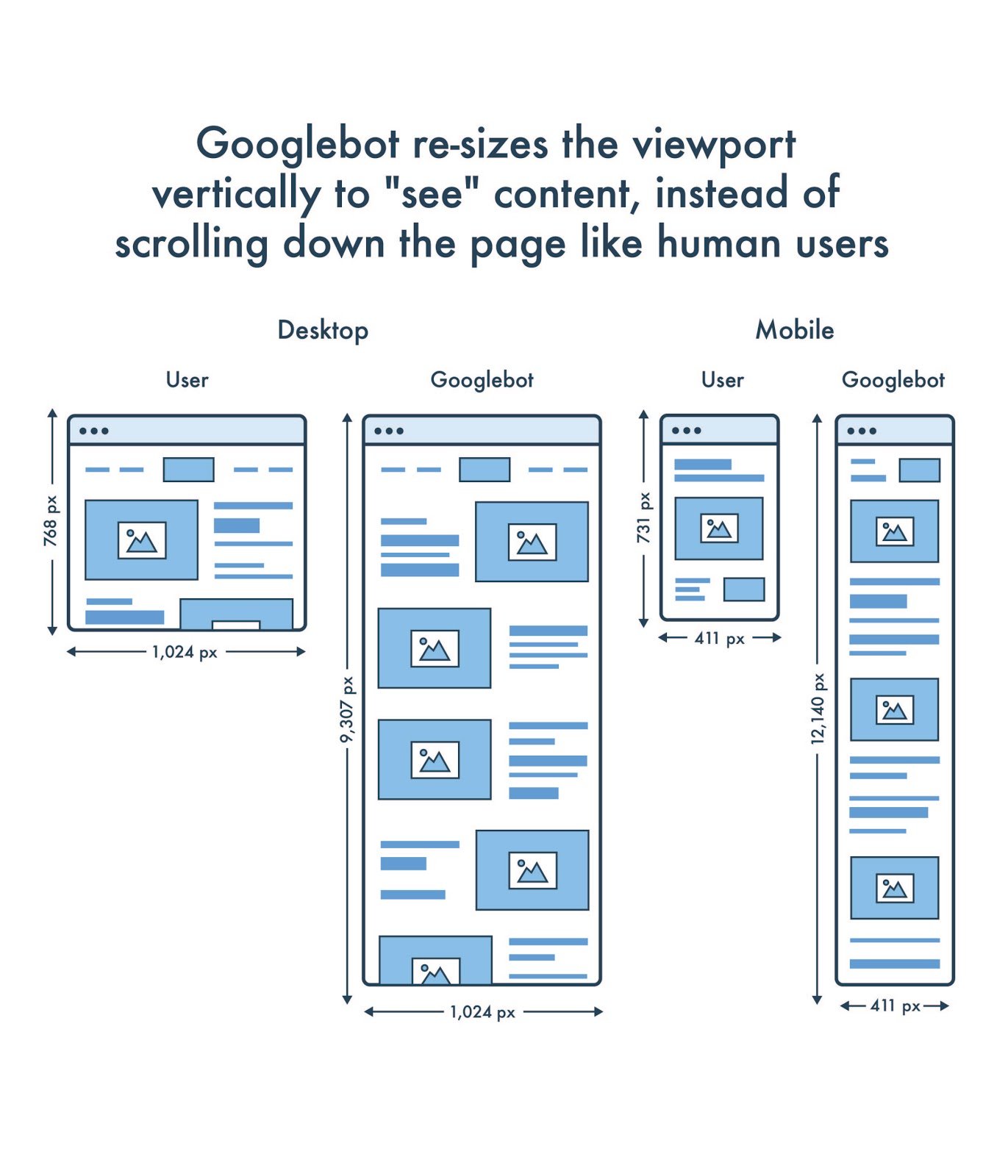
Googlebot supports lazy-loading, but it does not “scroll” like a human user would when visiting your web pages. Instead, Googlebot simply resizes its virtual viewport to be longer when crawling web content. Therefore, the “scroll” event listener is never triggered and the content is never rendered by the crawler.
Here’s an example of more SEO-friendly code:
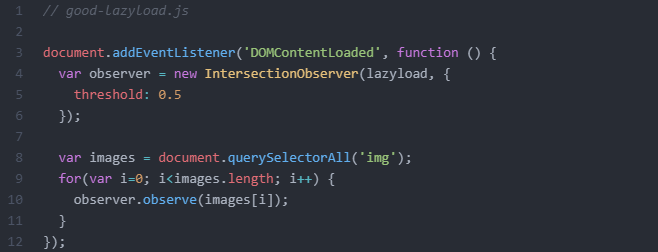
This code shows that the IntersectionObserver API triggers a callback when any observed element becomes visible. It’s more flexible and robust than the on-scroll event listener and is supported by modern Googlebot. This code works because of how Googlebot resizes its viewport in order to “see” your content (see below).
You can also use native lazy-loading in the browser. This is supported by Google Chrome, but note that it is still an experimental feature. Worst case scenario, it will just get ignored by Googlebot, and all images will load anyway:


Potential SEO issues: Similar to core content not being loaded, it’s important to make sure that Google is able to “see” all of the content on a page, including images. For example, on an e-commerce site with multiple rows of product listings, lazy-loading images can provide a faster user experience for both users and bots!
Javascript SEO for page speed
Javascript can also affect page load times, which is an official ranking factor in Google’s mobile-first index. This means that a slow page could potentially harm rankings in search. How can we help developers mitigate this?
- Minifying JavaScript
- Deferring non-critical JS until after the main content is rendered in the DOM
- Inlining critical JS
- Serving JS in smaller payloads
Potential SEO issues: A slow website creates a poor user experience for everyone, even search engines. Google itself defers loading JavaScript to save resources, so it’s important to make sure that any served to clients is coded and delivered efficiently to help safeguard rankings.
JavaScript SEO for meta data
Also, it’s important to note that SPAs that utilize a router package like react-router or vue-router have to take some extra steps to handle things like changing meta tags when navigating between router views. This is usually handled with a Node.js package like vue-meta or react-meta-tags.
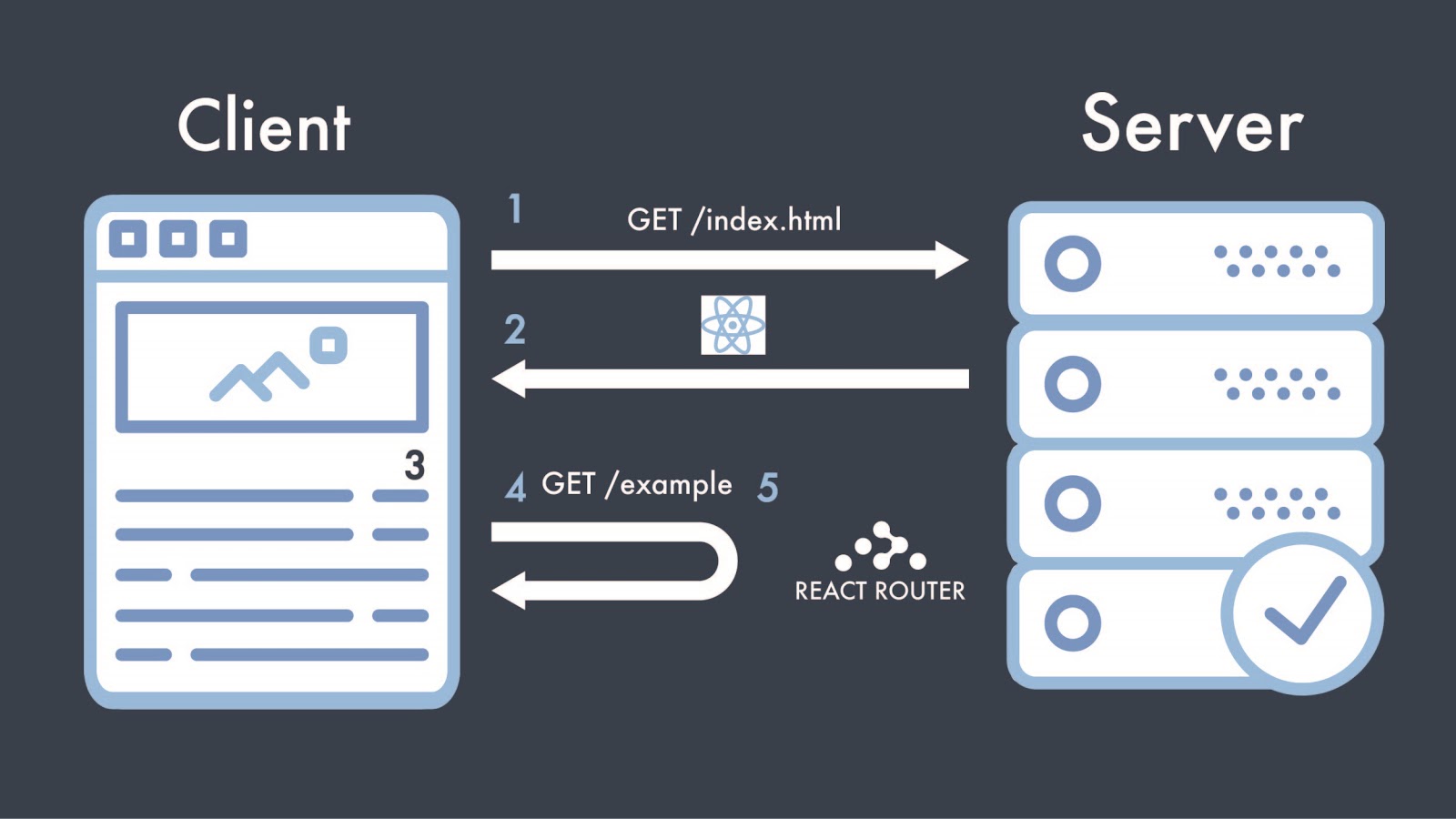
What are router views? Here’s how linking to different “pages” in a Single Page Application works in React in five steps:
- When a user visits a React website, a GET request is sent to the server for the ./index.html file.
- The server then sends the index.html page to the client, containing the scripts to launch React and React Router.
- The web application is then loaded on the client-side.
- If a user clicks on a link to go on a new page (/example), a request is sent to the server for the new URL.
- React Router intercepts the request before it reaches the server and handles the change of page itself. This is done by locally updating the rendered React components and changing the URL client-side.
In other words, when users or bots follow links to URLs on a React website, they are not being served multiple static HTML files. But rather, the React components (like headers, footers, and body content) hosted on root ./index.html file are simply being reorganized to display different content. This is why they’re called Single Page Applications!
Potential SEO issues: So, it’s important to use a package like React Helmet for making sure that users are being served unique metadata for each page, or “view,” when browsing SPAs. Otherwise, search engines may be crawling the same metadata for every page, or worse, none at all!
How does this all affect SEO in the bigger picture? Next, we need to learn how Google processes JavaScript.
How does Google handle JavaScript?
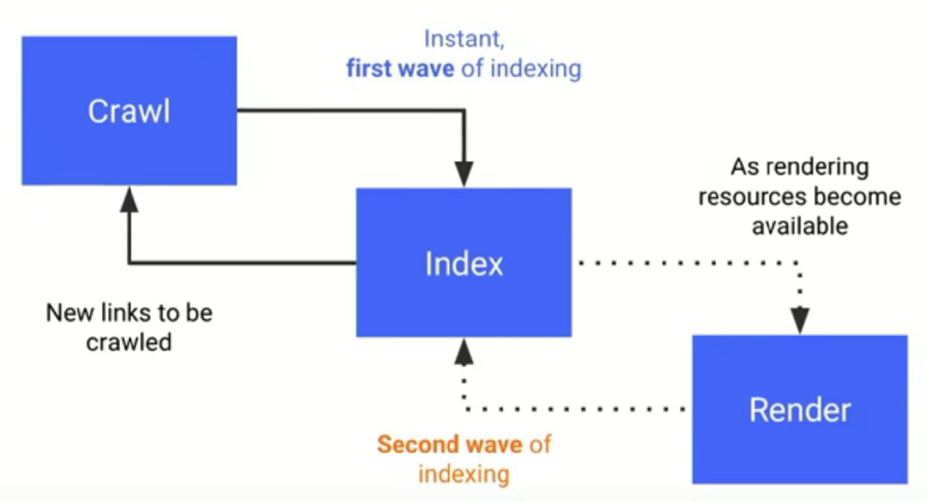
In order to understand how JavaScript affects SEO, we need to understand what exactly happens when GoogleBot crawls a web page:
- Crawl
- Render
- Index
First, Googlebot crawls the URLs in its queue, page by page. The crawler makes a GET request to the server, typically using a mobile user-agent, and then the server sends the HTML document.
Then, Google decides what resources are necessary to render the main content of the page. Usually, this means only the static HTML is crawled, and not any linked CSS or JS files. Why?
According to Google Webmasters, Googlebot has discovered approximately 130 trillion web pages. Rendering JavaScript at scale can be costly. The sheer computing power required to download, parse, and execute JavaScript in bulk is massive.
This is why Google may defer rendering JavaScript until later. Any unexecuted resources are queued to be processed by Google Web Rendering Services (WRS), as computing resources become available.
Finally, Google will index any rendered HTML after JavaScript is executed.
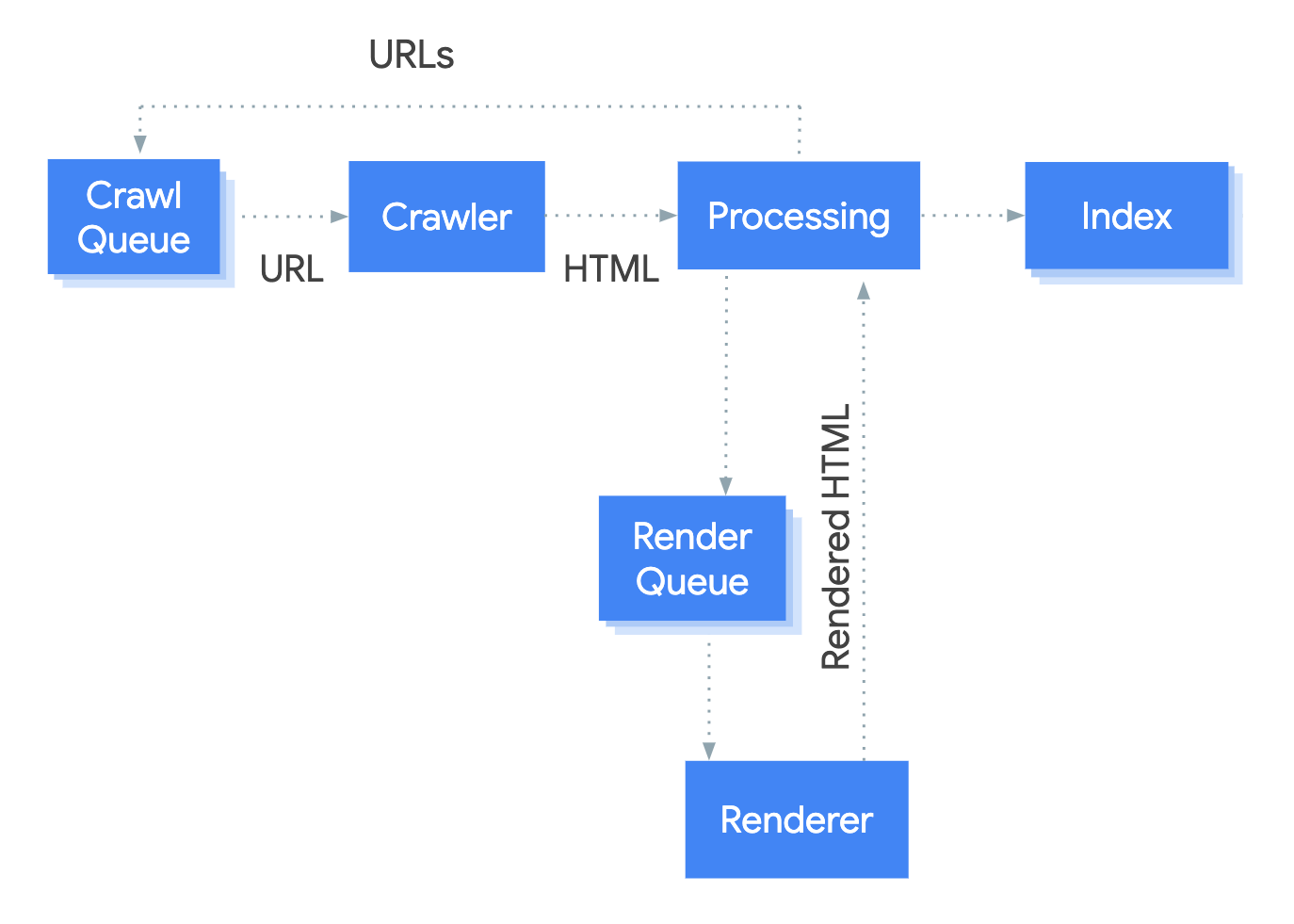
In other words, Google crawls and indexes content in two waves:
- The first wave of indexing, or the instant crawling of the static HTML sent by the webserver
- The second wave of indexing, or the deferred crawling of any additional content rendered via JavaScript
The bottom line is that content dependent on JS to be rendered can experience a delay in crawling and indexing by Google. This used to take days or even weeks. For example, Googlebot historically ran on the outdated Chrome 41 rendering engine. However, they’ve significantly improved its web crawlers in recent years.
Googlebot was recently upgraded to the latest stable release of the Chromium headless browser in May 2019. This means that their web crawler is now “evergreen” and fully compatible with ECMAScript 6 (ES6) and higher, or the latest versions of JavaScript.
So, if Googlebot can technically run JavaScript now, why are we still worried about indexing issues?
The short answer is crawl budget. This is the concept that Google has a rate limit on how frequently they can crawl a given website because of limited computing resources. We already know that Google defers JavaScript to be executed later to save crawl budget.
While the delay between crawling and rendering has been reduced, there is no guarantee that Google will actually execute the JavaScript code waiting in line in its Web Rendering Services queue.
Here are some reasons why Google might not actually ever run your JavaScript code:
- Blocked in robots.txt
- Timeouts
- Errors
Therefore, JavaScript can cause SEO issues when core content relies on JavaScript but is not rendered by Google.
Real-world application: JavaScript SEO for e-commerce
E-commerce websites are a real-life example of dynamic content that is injected via JavaScript. For example, online stores commonly load products onto category pages via JavaScript.
JavaScript can allow e-commerce websites to update products on their category pages dynamically. This makes sense because their inventory is in a constant state of flux due to sales. However, is Google actually able to “see” your content if it does not execute your JS files?
For e-commerce websites, which depend on online conversions, not having their products indexed by Google could be disastrous.
How to test and debug JavaScript SEO issues
Here are steps you can take today to proactively diagnose any potential JavaScript SEO issues:
- Visualize the page with Google’s Webmaster Tools. This helps you to view the page from Google’s perspective.
- Use the site search operator to check Google’s index. Make sure that all of your JavaScript content is being indexed properly by manually checking Google.
- Debug using Chrome’s built-in dev tools. Compare and contrast what Google “sees” (source code) with what users see (rendered code) and ensure that they align in general.
There are also handy third-party tools and plugins that you can use. We’ll talk about these soon.
Google Webmaster Tools
The best way to determine if Google is experiencing technical difficulties when attempting to render your pages is to test your pages using Google Webmaster tools, such as:
- URL Inspection tool in Search Console
- Mobile-Friendly Test
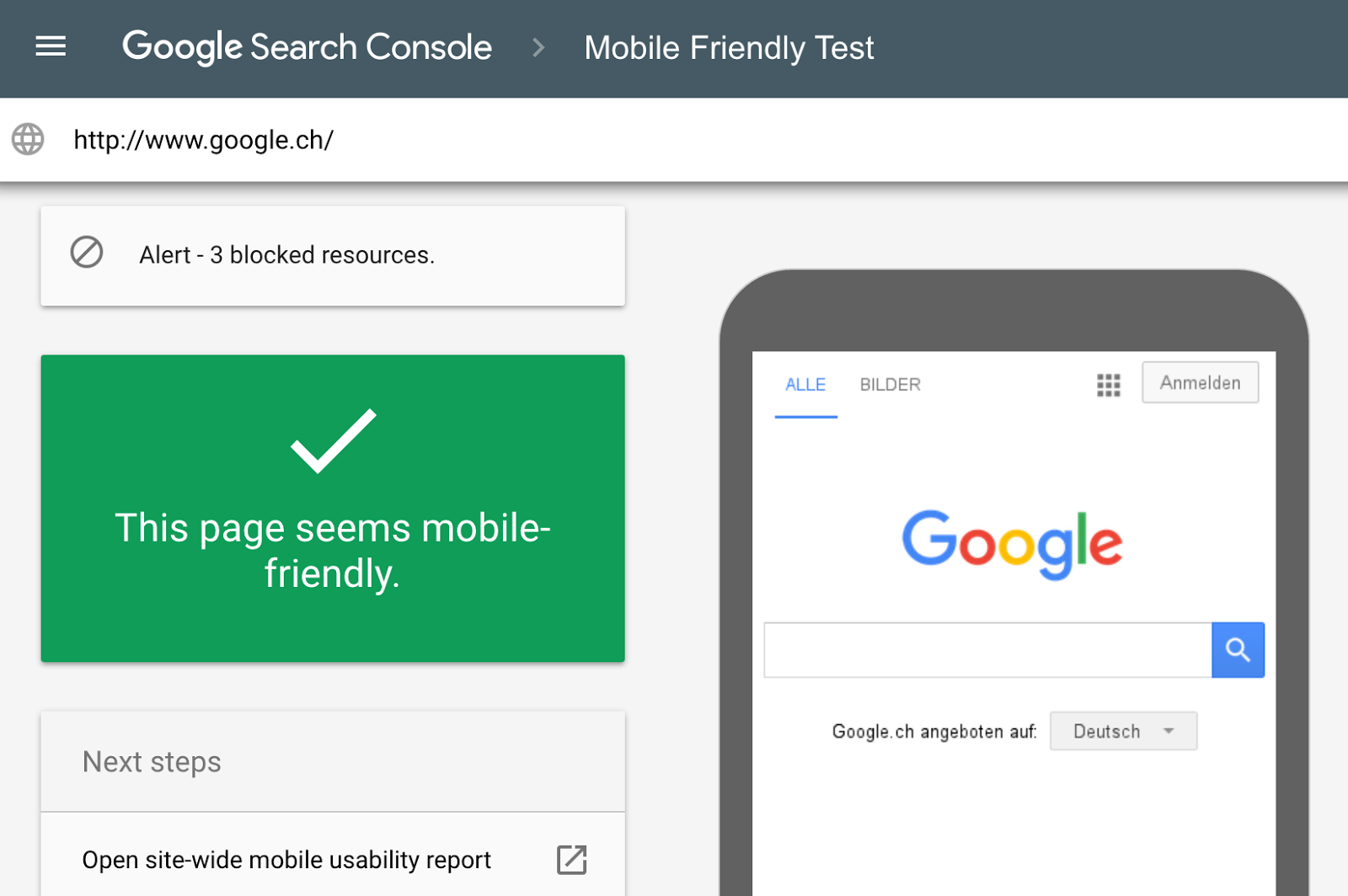
The goal is simply to visually compare and contrast your content visible in your browser and look for any discrepancies in what is being displayed in the tools.
Both of these Google Webmaster tools use the same evergreen Chromium rendering engine as Google. This means that they can give you an accurate visual representation of what Googlebot actually “sees” when it crawls your website.
There are also third-party technical SEO tools, like Merkle’s fetch and render tool. Unlike Google’s tools, this web application actually gives users a full-size screenshot of the entire page.
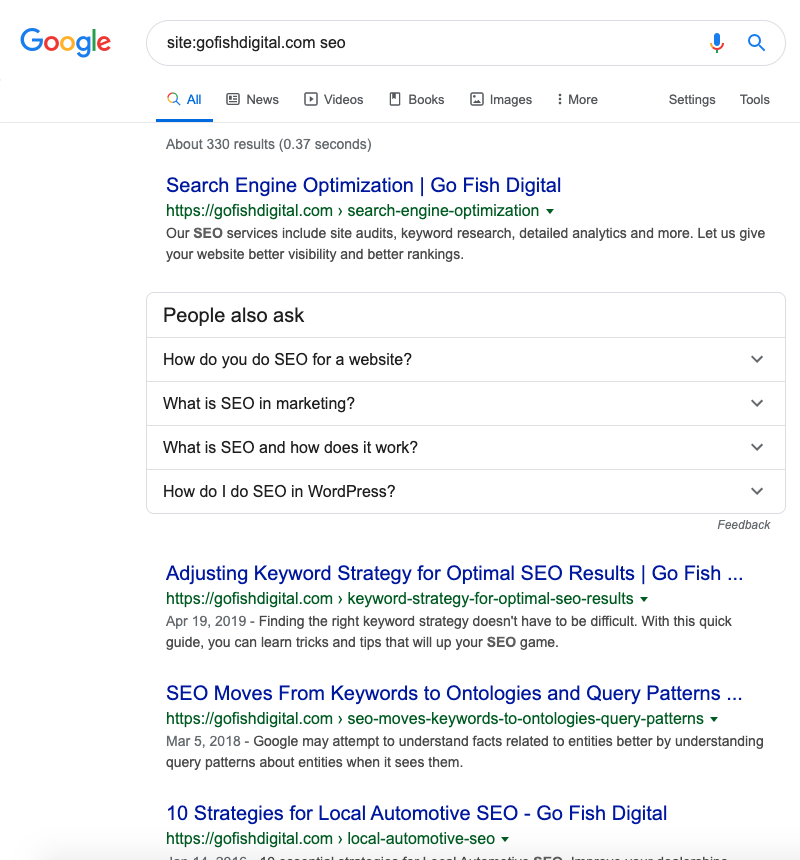
Site: Search Operator
Alternatively, if you are unsure if JavaScript content is being indexed by Google, you can perform a quick check-up by using the site: search operator on Google.
Copy and paste any content that you’re not sure that Google is indexing after the site: operator and your domain name, and then press the return key. If you can find your page in the search results, then no worries! Google can crawl, render, and index your content just fine. If not, it means your JavaScript content might need some help gaining visibility.
Here’s what this looks like in the Google SERP:
Chrome Dev Tools
Another method you can use to test and debug JavaScript SEO issues is the built-in functionality of the developer tools available in the Chrome web browser.
Right-click anywhere on a web page to display the options menu and then click “View Source” to see the static HTML document in a new tab.
You can also click “Inspect Element” after right-clicking to view the content that is actually loaded in the DOM, including JavaScript.
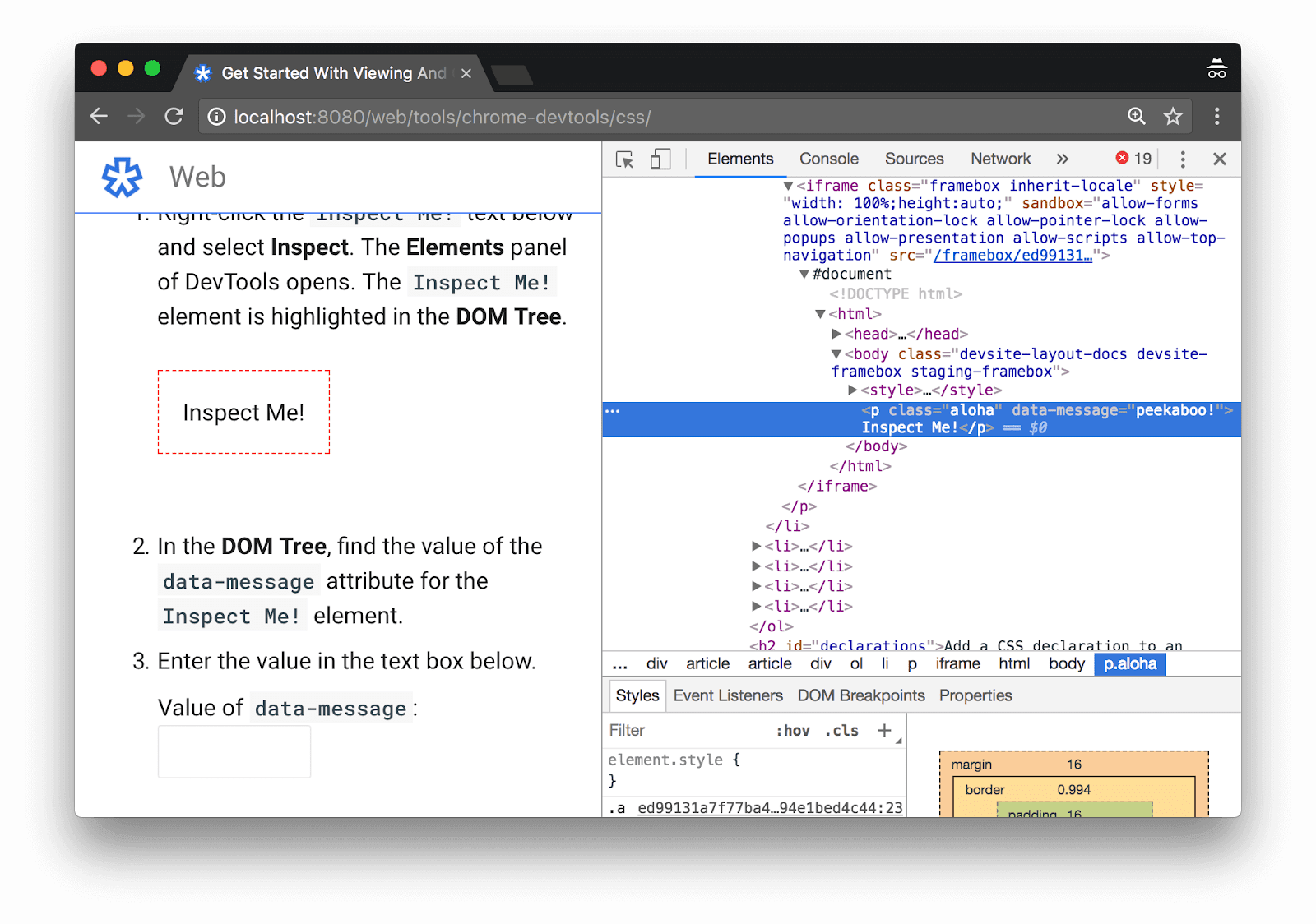
Compare and contrast these two perspectives to see if any core content is only loaded in the DOM, but not hard-coded in the source. There are also third-party Chrome extensions that can help do this, like the Web Developer plugin by Chris Pederick or the View Rendered Source plugin by Jon Hogg.
How to fix JavaScript rendering issues
After diagnosing a JavaScript rendering problem, how do you resolve JavaScript SEO issues? The answer is simple: Universal Javascript, also known as “Isomorphic” JavaScript.
What does this mean? Universal or Isomorphic here refers to JavaScript applications that are capable of being run on either the server or the client.
There are a few different implementations of JavaScript that are more search-friendly than client-side rendering, to avoid offloading JS to both users and crawlers:
- Server-side rendering (SSR). This means that JS is executed on the server for each request. One way to implement SSR is with a Node.js library like Puppeteer. However, this can put a lot of strain on the server.
- Hybrid rendering. This is a combination of both server-side and client-side rendering. Core content is rendered server-side before being sent to the client. Any additional resources are offloaded to the client.
- Dynamic rendering. In this workaround, the server detects the user agent of the client making the request. It can then send pre-rendered JavaScript content to search engines, for example. Any other user agents will need to render their content client-side. For example, Google Webmasters recommend a popular open-source solution called Renderton for implementing dynamic rendering.
- Incremental Static Regeneration, or updating static content after a site has already been deployed. This can be done with frameworks like Next.js for React or Nuxt.js for Vue. These frameworks have a build process that will pre-render every page of your JS application to static assets that you can serve from something like an S3 bucket. This way, your site can get all of the SEO benefits of server-side rendering, without the server management!
Each of these solutions helps make sure that, when search engine bots make requests to crawl HTML documents, they receive the fully rendered versions of the web pages. However, some of these can be extremely difficult or even impossible to implement after web infrastructure is already built. That’s why it’s important to keep JavaScript SEO best practices in mind when designing the architecture of your next web application.
Note, for websites built on a content management system (CMS) that already pre-renders most content, like WordPress or Shopify, this isn’t typically an issue.
Key takeaways
This guide provides some general best practices and insights into JavaScript SEO. However, JavaScript SEO is a complex and nuanced field of study. We recommend that you read through Google’s official documentation and troubleshooting guide for more JavaScript SEO basics. Interested in learning more about optimizing your JavaScript website for search? Leave a comment below.